Как процессы в системе взаимодействуют между собой?
Трубы(пайпы ‘|’) — связь между двумя взаимосвязанными процессами. Механизм является полудуплексным, что означает, что первый процесс связан со вторым процессом. Для достижения полного дуплекса, т. Е. Для взаимодействия второго процесса с первым процессом требуется другой канал.
FIFO — Связь между двумя не связанными процессами. FIFO — это полный дуплекс, что означает, что первый процесс может взаимодействовать со вторым процессом и наоборот одновременно.
Очереди сообщений — связь между двумя или более процессами с полной дуплексной пропускной способностью. Процессы будут связываться друг с другом, отправляя сообщение и извлекая его из очереди. Полученное сообщение больше не доступно в очереди.
Совместно используемая память. Связь между двумя или более процессами достигается за счет совместного использования памяти всеми процессами. Совместно используемая память должна быть защищена друг от друга путем синхронизации доступа ко всем процессам.
Семафоры — семафоры предназначены для синхронизации доступа к нескольким процессам. Когда один процесс хочет получить доступ к памяти (для чтения или записи), он должен быть заблокирован (или защищен) и освобожден при удалении доступа. Это должно быть повторено всеми процессами для защиты данных.
Сигналы — Сигнал — это механизм связи между несколькими процессами посредством сигнализации. Это означает, что исходный процесс отправит сигнал (распознанный по номеру), а целевой процесс обработает его соответствующим образом.
Примечание. Почти все программы в этом руководстве основаны на системных вызовах в операционной системе Linux (выполняется в Ubuntu).
Где в системе можно посмотреть сводку по текущему потреблению памяти?
free -m total used free shared buff/cache available
Mem: 3923 309 231 2 3382 3318
Swap: 0 0 0Эта утилита не показывает физическое количество памяти.
Она показывает сколько памяти доступно в системе.
То есть физически сколько заняло ядро.
total — 3923 мегабайт — Она показывает сколько памяти у нас в системе.used — 309 мегабайт — сколько у нас памяти занимают исполняемые процессы.free — 231 мегабайт — ненужная в данный момент память. То есть если надо будет системе — она ее займет.shared — 2 мегабайта — shared память для межпроцессорного взаимодействия. Чтобы поделиться памятью из одного процессора в другой.buff/cache — буффер — память для компоновки данных. Страничный кэш — это то, с помощью чего мы например можем файлы открывать.
Почему линукс съедает память? Потому что процесс который запрашивает данные из файла на диски — он данные выгружает в оперативную память.
Чем больше процессов просит данных — тем больше кэша, свободной памяти становится меньше.
Однако, единожды загруженный файл в кеш — может там остаться даже если приложение, которое это инициировало — завершилось.
Поскольку операции доступа до диска это дорогие по времени операции.
И ядро считает, что стоит сохранить какие-то из данных, не чистить их сразу. На тот случай, если кому-то еще эти данные понадобятся.
Итого свободная память — это та память которая ни нужна ни для кэша, ни для чего-то ещё.available — 3381 мегабайт может быть доступно в случае необходимости.
Если available нет, то его в примерном виде можно посчитать так: free + 70% от кэша.
Ибо не во всех дистрибутивах этот показатель есть.
Какие ситуации будут указывать на возможную проблему?
- Available память или ( free -/+ buffers/cache ) близки к нулю или очень маленькое значение.
- В логах ядра есть сообщения
OutOfMemory. (dmesg -T | grep out of memory)
Что такое виртуальная память?
Виртуальная память (или «логическая память») — это метод управления памятью, осуществляемый операционной системой, который позволяет программам задействовать значительно больше памяти, чем фактически установлено в компьютере.
Например, если объем физической памяти компьютера составляет 4 ГБ, а виртуальной 16 ГБ, то программе может быть доступен объем виртуальной памяти вплоть до 16 ГБ.
Основное различие между физической и виртуальной памятью заключается в том, что физическая память относится к оперативной памяти компьютера, подключенной непосредственно к его материнской плате.
Именно в ней находятся выполняемые в данный момент программы. А виртуальная память — это метод управления, расширяющий при помощи жесткого диска объем физической памяти, благодаря чему у пользователей появляется возможность запускать программы, требование к памяти которых превышает объем установленной в компьютере физической памяти.

Что такое load average? Что показывает эта метрика? Почему load average состоит из трёх значений?
Часто говорят что это средняя загрузка процессора или нагрузка системы, или какие-то циферки. Узнать значение la можно разными способами. Например, uptime, top, и другими командами.
Принято считать, что какое-то стабильное значение этих цифр отражает стабильное поведение системы. Появление всплеска может означать появление проблемы в системе. Что-то идет не так, копятся процессы. Цифры обозначают нагрузку за определенный период времени. 1, 5 и 15 минут. (Это важно учесть, это все рассчитывается для предыдущего времени. И когда вы заходите на сервер спустя минуту — там может ничего не быть)
Определение LA по сути — эта цифра показывает количество процессов в статусе d r (ожидание, запущено соответственно) А дальше уже всё будет зависеть от ситуации. Допустим у нас сервер есть где постоянно на диски пишутся резервные копии. Там LA будет высокая скорее всего. Просто потому что есть процессы в статусе d, которые копятся из-за того, что диск занят. Но на работу системы в целом это может не влиять вообще.
Если процессов скопилось много там, где это не ожидается, ну там сервера с сайтами, базами данных, с php-fpm, nginx и прочим таким, то смотрим через top -cHi -d1 что там именно скопилось. И в таких вот случаях сервер может тупить, ибо будут копиться процессы в статусе r. Из-за чего работа сервера будет медленной. Даже по ssh иногда не зайти будет.
Если коротко это кол-во процессов и операций ввода/вывода которые находяться в ожидание процессорного времени(исполнения процессором) за 1, 5, 15 минут
Какие сигналы не могут быть проигнорированы?
SIGSTOP — принудительная остановка процессаSIGKILL — немедленное завершение процесса
Что показывает статус процессов? Какие статусы используются в linux?
R — процесс исполнется, или ждет своей очереди на исполнениеS — прерываемый сон — процесс ожидает определенного события или сигнала.
Нужен, когда процесс нельзя завершить (чтение из файла), ядро переводит на ожидание.
Ожидать данные от сетевого соединенияD — непрерывное ожидание, сон. Ждем сигнал от аппаратной части.
T — остановка процесса, посылаем сигнал STOP. В этом состоянии процессу запрещено выполняться
Чтобы вернуть к жизни нужно послать CONT
При завершении процесса он становится зомбиZ(zombie) — зомби это процесс, который закончил выполнение, но не передал родительскому процессу
свой код возвращения. Процесс в этом состоянии игнорирует kill.
Родитель получает код, и освобождает структуру ядра, которое относится к процессу
Бывает еще когда родительский умирает раньше дочернего. Процесс становится сиротой.
Что означает каждая запись в выводе команды top?
top - 10:44:36 up 91 days, 19:29, 7 users, load average: 0,00, 0,02, 0,05
Tasks: 156 total, 1 running, 155 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0,0 us, 1,5 sy, 0,0 ni, 96,9 id, 0,0 wa, 0,0 hi, 0,0 si, 1,5 st
KiB Mem : 12137392 total, 6227844 free, 1117728 used, 4791820 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 10090148 avail Memtop — утилита
10:44:36 — время системы
up — сколько система работает с момента последнего запуска
7 user — количество авторизованных юзеров в системе
load average: 0.00, 0.02, 0.05 — параметр средней нагрузки на систему за период времени 1 минута, 5 минут, 15 минут
156 total — всего процессов в системе
1 running — количество процессов в работе
155 sleeping — ожидание процесса или сигнала
0 stopped — количество приостановленных процессов сигналом STOP или выполнение трассировки
0 zombie — количество зомби-процессов, которые завершили своё выполнение, но присутствующие в системе, чтобы дать родительскому процессу считать свой код завершения.
| параметр | описание |
|---|---|
us (user) | Использование процессора пользовательским процессами |
sy (system) | Использование процессора системным процессами |
ni (nice) | Использование процессора процессами с измененным приоритетом с помощью команды nice |
id (idle) | Простой процессора. Можно сказать, что это свободные ресурсы |
wa (IO-wait) | Время на простой, то есть ожидания переферийных устройств ввода вывода |
hi (hardware interrupts) | Показывает сколько процессорного времени было потрачено на обслуживание аппаратного прерывания. (Аппаратные прерывания генерируются аппаратными устройствами. Сетевыми картами, клавиуатурами, датчиками, когда им нужно о чем-то просигнализировать цп. |
si (software interrupts) | Показывает сколько процессорного времени было потрачено на обслуживание софтверного прерывания. Фрагмент кода, вызывающий процедуру прерывания |
st (stolen by the hypervisor) | Показывает сколько процессорного времени было «украдено» гипервизором. Для запуска виртуальной машины, или для иных нужд |
**KiB Mem** - количество оперативной памяти в кибибайтах (кратно 1024): *7106404 total* -- всего доступно оперативной памяти в системе, *306972 free* -- свободно оперативной памяти для использования, *3127144 used* -- использовано оперативной памяти, *3672288 buff/cache* -- буферизовано/закешировано оперативной памяти.
**KiB Swap** - количество swap-памяти в кибибайтах (кратно 1024), которые выделено на диске: *8191996 total* - всего выделено swap-памяти, *8191996 free* - свободно swap-памяти *0 used* - использовано swap-памяти, *3270520 avail Mem* - доступно для использования swap-памяти.Что такое userspace, kernelspace? Чем они отличаются?
Под пользовательским пространством понимается весь код операционной системы, который находится вне ядра.
Большинство Unix-подобных операционных систем (включая Linux) поставляются с разнообразными предустановленными утилитами, средствами разработки и графическими инструментами — это все приложения пространства пользователя.
Все пользовательские приложения (и контейнеризированные и нет) при работе используют различные данные, но где эти данные хранятся?
Какие-то данные поступают из регистров процессора и внешних устройств, но чаще они хранятся в памяти и на диске. Приложения получают доступ к данным, выполняя специальные запросы к ядру — системные вызовы. Например, такие как выделение памяти (для переменных) или открытие файла. В памяти и файлах часто хранится конфиденциальная информация, принадлежащая разным пользователям, поэтому доступ к ним должен запрашиваться у ядра с помощью системных вызовов.
Ядро обеспечивает абстракцию для безопасности, оборудования и внутренних структур данных. Например, системный вызов open() используется для получения дескриптора файла в Python, C, Ruby и других языках программирования. Вряд ли бы вы хотели, чтобы ваша программа работала с XFS на уровне битов, поэтому ядро предоставляет системные вызовы и работает с драйверами. Фактически этот системный вызов настолько распространен, что является частью библиотеки POSIX.
Что значит $@, $!, $?, $$ в bash?
$@ — показывает все параметры переданные скрипту.$! — показывает pid последнего процесса, которая оболочка запустила в фоновом режиме.$$ — показывает текущий pid процесса.$? — показывает с каким кодом завершилась последняя выполненная функция. 0 — успешное выполнение.
Какие есть best practices для написания Dockerfile?
- Запускать только один процесс на контейнер.
- Стараться объединять несколько команд RUN в одну для уменьшения количества слоёв образа.
- Частоизменяемые слои образа необходимо располагать ниже по уровню, чтобы ускорить процесс сборки, т.к. при изменении верхнего слоя, все нижеследующие слои будут пересобираться.
- Указывать явные версии образов в инструкции FROM, чтобы избежать случая, когда выйдет новая версия образа с тегом latest.
- При установке пакетов указывать версии пакетов.
- Очищать кеш пакетного менеджера и удалять ненужные файлы после выполненной инструкции.
- Использовать multistage build для сборки артифакта в одном контейнере и размещении его в другом.
Какие инструкции есть у Dockerfile?
| Инструкция | Описание |
|---|---|
| FROM | Задаёт базовый (родительский) образ. |
| LABEL | Описывает метаданные. Например — сведения о том, кто создал и поддерживает образ. |
| ENV | Устанавливает постоянные переменные среды. |
| RUN | Выполняет команду и создаёт слой образа. Используется для установки в контейнер пакетов. |
| COPY | Копирует в контейнер файлы и директории. |
| ADD | Копирует файлы и директории в контейнер, может распаковывать локальные .tar-файлы. |
| CMD | Описывает команду с аргументами, которую нужно выполнить когда контейнер будет запущен. Аргументы могут быть переопределены при запуске контейнера. В файле может присутствовать лишь одна инструкция CMD. |
| WORKDIR | Задаёт рабочую директорию для следующей инструкции. |
| ARG | Задаёт переменные для передачи Docker во время сборки образа. |
| ENTRYPOINT | Предоставляет команду с аргументами для вызова во время выполнения контейнера. Аргументы не переопределяются. |
| EXPOSE | Указывает на необходимость открыть порт. |
| VOLUME | Создаёт точку монтирования для работы с постоянным хранилищем. |
Какие DNS записи бывают? Что такое DKIM, DMARC, PTR?
Основные DNS записи:
| Тип | Расшифрока | Описание |
|---|---|---|
| A | Address | Адресная запись, соответствие между именем и IP-адресом. |
| AAAA | Address v6 | Аналог A записи для IPv6 адресов. |
| CNAME | Canonical Name | Каноническое имя для псевдонима (одноуровневая переадресация) |
| MX | Mail Exchanger | Адрес почтового шлюза для домена. Состоит из двух частей — приоритета (чем число больше, тем ниже приоритет), и адреса узла. |
| NS | Authoritative name server | Адрес узла, отвечающего за доменную зону. Критически важна для функционирования самой системы доменных имён. |
| PTR | Pointer | Соответствие адреса имени — обратное соответствие для A и AAAA. |
| SOA | Start of authority | Указание на авторитетность информации, используется для указания на новую зону. |
| TXT | Text string | Запись произвольных двоичных данных, до 255 байт в размере. |
| SPF | Sender Policy Framework | Указывает серверы, которые могут отправлять почту с данного домена. |
DomainKeys Identified Mail (DKIM) — метод E-mail аутентификации, разработанный для обнаружения подделывания сообщений, пересылаемых по email. Метод дает возможность получателю проверить, что письмо действительно было отправлено с заявленного домена. DKIM упрощает борьбу с поддельными адресами отправителей, которые часто используются в фишинговых письмах и в почтовом спаме.
Domain-based Message Authentication, Reporting and Conformance (идентификация сообщений, создание отчётов и определение соответствия по доменному имени) или DMARC — это техническая спецификация, созданная группой организаций, предназначенная для снижения количества спамовых и фишинговых электронных писем, основанная на идентификации почтовых доменов отправителя на основании правил и признаков, заданных на почтовом сервере получателя.
Информация о DKIM и DMARC устанавливается в TXT записи домена.
Как происходит соединение TCP?
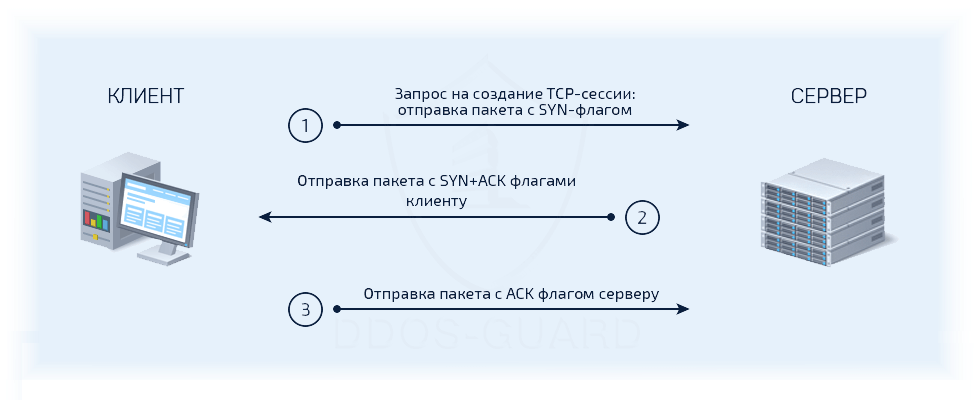
- Клиент, который намеревается установить соединение, посылает серверу сегмент с номером последовательности и флагом
SYN. Дальнейший алгоритм: Сервер получает сегмент, запоминает номер последовательности и пытается создать сокет (буферы и управляющие структуры памяти) для обслуживания нового клиента; В случае успеха сервер посылает клиенту сегмент с номером последовательности и флагамиSYNиACK, и переходит в состояниеSYN-RECEIVED;В случае неудачи сервер посылает клиенту сегмент с флагом RST. - Если клиент получает сегмент с флагом
SYN, то он запоминает номер последовательности и посылает сегмент с флагом ACK. Дальнейший алгоритм: Если он одновременно получает и флаг ACK (что обычно и происходит), то он переходит в состояниеESTABLISHED; Если клиент получает сегмент с флагом RST, то он прекращает попытки соединиться; Если клиент не получает ответа в течение 10 секунд, то он повторяет процесс соединения заново. - Если сервер в состоянии
SYN-RECEIVEDполучает сегмент с флагом ACK, то он переходит в состояниеESTABLISHED. В противном случае после тайм-аута он закрывает сокет и переходит в состояниеCLOSED. Процесс называется «трёхэтапным рукопожатием» (англ. three way handshake), так как несмотря на то что возможен процесс установления соединения с использованием четырёх сегментов (SYN в сторону сервера, ACK в сторону клиента, SYN в сторону клиента, ACK в сторону сервера), на практике для экономии времени используется три сегмента.
Чем отличается TCP от UDP? Что лучше?
TCP – транспортный протокол передачи данных в сетях TCP/IP, предназначен для управления передачей данных интернета. Пакеты в TCP называются сегментами. Ориентирован на соединение, используется для передачи данных (электронная почта, файлы, сообщения). При определении потери пакетов будет выполнен перезапрос потерянных пакетов.
UDP – транспортный протокол, передающий сообщения-датаграммы без необходимости установки соединения в IP-сети. Не ориентирован на установление соединения, используется в потоковой передаче данных (IPTV, VoIP). При потере пакетов перезапроса потерянных пакетов не происходит.
Нельзя сказать, что TCP лучше UDP, т.к. данные транспортные протоколы используются для различных типов передачи трафика.
Что такое протокол IP?
IP (Internet Protocol) — протокол сетевого уровня стека TCP/IP.
Основной задачей протокола является доставка датаграмм между хостами сетей TCP/IP через произвольное число промежуточных узлов (маршрутизаторов).
Функции, реализуемые IP:
- Основа передачи данных.
- Адресация.
- Маршрутизация.
- Фрагментация датаграмм. Протокол IP не гарантирует надежной доставки пакета: пакеты могут прийти в неправильном порядке, пакет может быть утерян, пакет может продублироваться или оказаться поврежденным. За надежность доставки пакетов отвечают протоколы транспортного уровня.
На данный момент наиболее распространена четвертая версия протокола (IPv4), однако ведутся активные работы по внедрению более совершенного IPv6.
Как работает sudo и почему не стоит логиниться под root?
Работать напрямую под пользователем root — всё равно что держать гранату без чеки. Этот аккаунт имеет неограниченные права, и любая ошибка — даже случайный пробел или лишний символ — может:
• удалить системные файлы,
• повредить загрузку,
• нарушить безопасность сервера.
Особенно опасно это на удалённых машинах, где откат может быть невозможен, и в многопользовательских системах, где нужен контроль за действиями каждого.
Команда sudo (SuperUser DO) даёт точечный доступ к правам администратора. Вместо входа под root ты запускаешь конкретную команду от его имени.
Пример правильного подхода:
sudo apt install nginxУстановка пакета через sudo. Система запросит пароль и выполнит только эту команду с повышенными правами.
Плохая альтернатива:
su
# или
ssh root@ipКоманда su полностью переключает пользователя на root, а прямой SSH-доступ — даёт полный контроль без ограничений. Эти действия не логируются, не ограничиваются и мгновенно открывают весь доступ к системе.
Так что:
sudo = точечный доступ с контролем и безопасностью.
root-доступ = постоянный риск, отсутствие логов, плохая практика.
Сканируем порты с Rustscan
Это современная альтернатива nmap: работает быстрее, но результат можно передавать прямо в nmap для глубокого анализа.
Минимальный пример сканирования:
rustscan -a 192.168.1.1Опция -a указывает цель, Rustscan проверит открытые порты.
Хотим ускорить скан? Задаём количество потоков:
rustscan -a 192.168.1.1 -b 500Флаг -b управляет количеством параллельных запросов.
Чтобы сразу передать результат в nmap:
rustscan -a 192.168.1.1 -- -sVПосле -- все параметры идут в nmap. Здесь -sV проверяет версии сервисов.
Это удобно для быстрых проверок и отлично сочетается с классическим nmap для детальной информации.
Смотрим, кто и когда логинился в систему
Для анализа активности пользователей в Linux можно использовать стандартные утилиты — last, who и w.
Они читают данные из системных логов (/var/log/wtmp, utmp) и показывают время входа, IP-адрес, а иногда и то, чем занят пользователь.
Показываем историю входов:
lastВыведет список логинов и логаутов с датами, IP/tty и длительностью сессии. Полезно для расследования взломов.
Смотрим, кто в системе прямо сейчас:
whoПоказывает активных пользователей, их терминалы, время входа и IP. Быстрое средство проверки.
Проверяем, что делают пользователи:
wДаёт расширенную картину — время бездействия, нагрузку на систему, выполняемые команды.
Эти команды помогают при расследовании инцидентов, аудите безопасности и даже в CTF. Доступ к /var/log/wtmp обязателен, иначе вывод будет пустым.
Проверяем использование памяти через free и vmstat
Проверяем использование памяти через free и vmstat → быстрый анализ RAM, swap и нагрузки!
Хочешь быстро узнать, куда уходит память и почему система тормозит? В Linux есть встроенные утилиты free и vmstat, которые показывают состояние RAM, swap и нагрузку на систему — без лишних тулов.
Сначала глянем базовую инфу о памяти:
free -h-h делает вывод в удобных единицах (MB/GB). Видим общую память, занятую, свободную и кэш/буфер.
Теперь более детальный мониторинг через vmstat:
vmstat 2 52 5 значит: обновлять каждые 2 секунды, всего 5 раз.
r — сколько процессов ждут CPU.
si/so — сколько данных подкачивается в/из swap.
us/sy/wa — загрузка CPU пользователем, системой и ожидание ввода-вывода.
Для удобства можно сразу смотреть, какие процессы жрут память:
ps aux --sort=-%mem | headСортировка по использованию памяти.
head показывает только топовые процессы.
Это поможет быстро понять, хватает ли RAM, лезет ли система в swap и кто реально нагружает память.
journalctl для быстрого анализа логов systemd
Используем journalctl для быстрого анализа логов systemd — компактно и практично!
Нужны логи конкретного сервиса (последние 200 строк, ISO-время, без пейджера):
journalctl -u sshd -n 200 -o short-iso --no-pagerСмотрим логи в реальном времени (follow) и только за последний час:
journalctl -u myapp.service -f --since "1 hour ago"Фильтруем по уровню ошибок и временному диапазону:
journalctl -u nginx -p err --since "2023-08-01 00:00" --until "2023-08-01 12:00"Экспортируем логи в файл для разбора или отправки в баг-репорт:
journalctl -u myapp.service --since today > /tmp/myapp-today.logПоднимаем простой HTTP-сервер одной командой — python -m http.server!
Нужен быстрый способ расшарить файлы или протестировать статические страницы без настройки Nginx? Встроенный модуль Python позволяет поднять сервер в любой папке за секунду.
Запуск в текущей директории на порту 8000, доступ с любого интерфейса и пример фонового старта с логом:
Запустить сервер (порт 8000, доступ с сети):
python3 -m http.server 8000 --bind 0.0.0.0То же в фоне с логом и сохранением PID:
nohup python3 -m http.server 8000 --bind 0.0.0.0 > http-server.log 2>&1 & echo $! > http-server.pidОстановить по PID:
kill "$(cat http-server.pid)" || trueКоротко о безопасности: не используйте этот сервер в открытом интернет-доступе — он не предназначен для продакшена.
Проверяем загрузку дисков с df и mount
Быстрая проверка свободного места и точек монтирования помогает поймать «взрывающийся» диск до инцидента.
df показывает размеры и заполнение, mount — где и как подключены файловые системы.
Общий обзор — показываем размер, тип FS и заполнение в удобном виде:
df -hTПроверяем использование inode (важно при большом количестве мелких файлов):
df -iСмотрим все точки монтирования и отформатируем вывод для удобства:
mount | column -tНаходим топ-10 директорий, которые «съедают» место в корне:
du -sh /* 2>/dev/null | sort -hr | head -n 10Следим в реальном времени за заполнением всех файловых систем:
watch -n 5 df -hЕсли видно >85–90% заполнение — настройте оповещения или очистку до того, как сервисy начнёт ломаться